Chapter 21 R Markdown
在 R 中,R Markdown 为数据科学提供了一个统一的创作框架,结合了代码、结果和文本创作。 同时这种文档完全可复制,并支持数十种导出格式,如 pdf、docx、pptx 等。
R Markdown 文件旨在以三种方式使用: - 为了与决策者沟通,他们希望看到结论,而不是分析背后的代码。 - 与其他数据科学家合作,方便快速得知结论和得出这些结论的过程(即代码)。 - 作为做数据科学的环境,作为现代实验室笔记本,你不仅可以捕捉你做了什么,还可以捕捉你的想法。
21.1 R Markdown 基础知识
一个简单的 .Rmd 文件应该包含:
- 可选的标头:
---
title: "Diamond sizes"
date: 2016-08-25
output: html_document
---- 一些被标识符包围的代码块:
```{R setup, include = FALSE}
library(ggplot2)
library(dplyr)
smaller <- diamonds %>%
filter(carat <= 2.5)
```- 混合了简单文本格式的文本(Markdown 语法)。
当你开一个 .Rmd 文件,你会得到一个笔记本界面,其代码和输出交织在一起。我们可以通过单击运行图标(看起来像块顶部的播放按钮)或按 Cmd/Ctrl + Shift + Enter 来运行每个代码块。
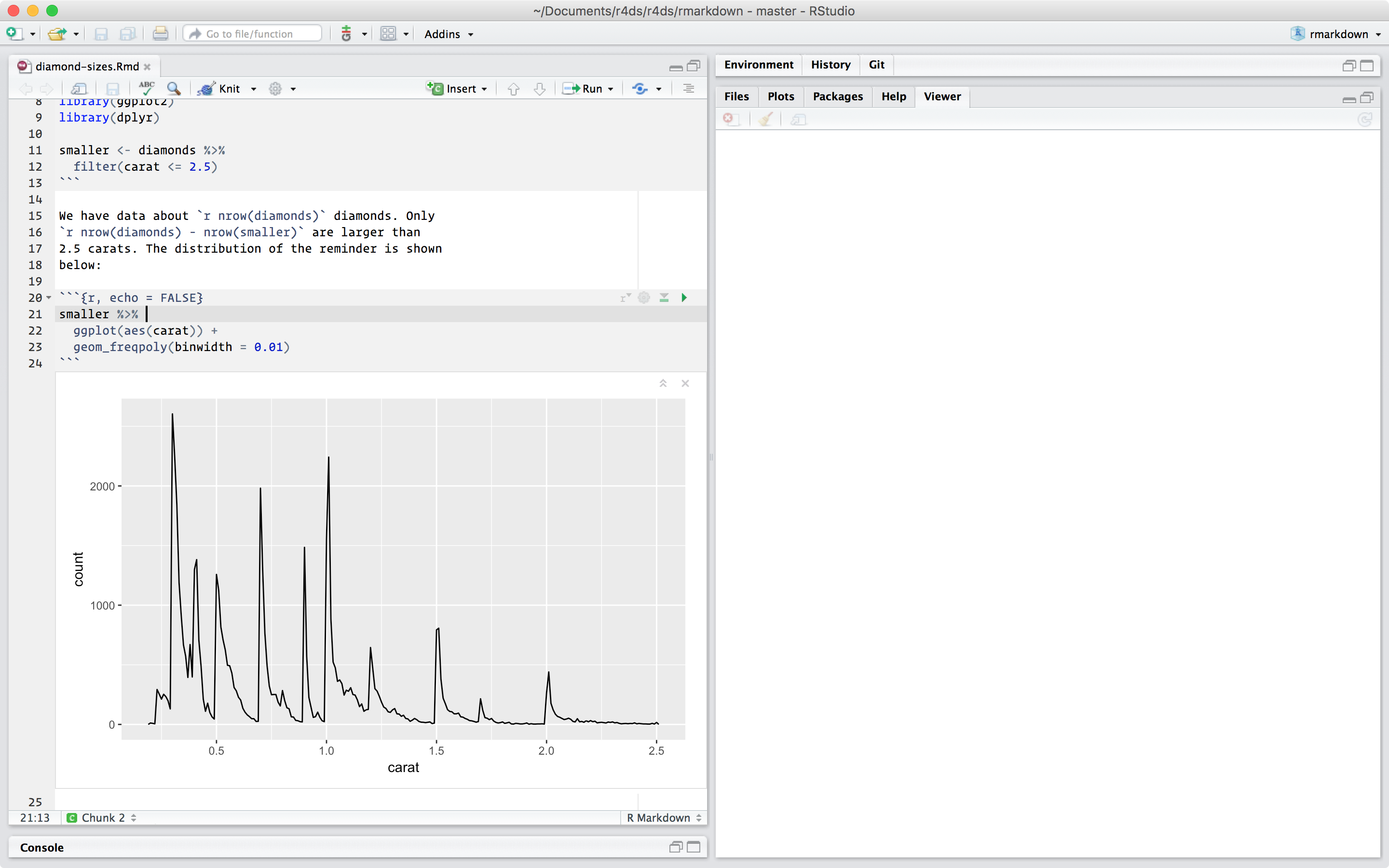
diamond-sizes-notebook
要生成包含所有文本、代码和结果的完整报告,请单击 “Knit Rmd” 或按Cmd/Ctrl + Shift + K。当然我们也可以以编程方式使用,如 rmarkdown::render("1-example.Rmd")。这将显示查看器窗格中的报告,并创建一个自包含的 HTML 文件,以便与他人共享。
当我们生成文档时,R Markdown 会发送 Rmd 文件到 knitr,它执行所有代码块,并创建一个新的 Markdown 文件,其中包括代码及其输出。随后其文档将被 pandoc 转换成任何你想要的文件格式。

rmarkdownflow
21.3 代码块
要在 R Markdown 文档中运行代码,我们需要插入一个块。有三种方法可以做到这一点:
1. 键盘快捷键 Cmd/Ctrl + Alt + I。
2. 编辑器工具栏中的 “插入” 按钮图标。
3. 通过手动键入块分隔符。
显然,我建议你学习键盘快捷键。从长远来看,这将为我们节省大量时间!
代码块还可以命名,如 {R by-name}。引索同样会检测并展示,方便你快速跳转。同时你也可以为它的功能做一些限制。下面是一些配置项(如果需要当然可以同时使用多个配置项):
| 选择 | 运行代码 | 显示代码 | 输出 | 运行过程 | 提示 | 警告 |
|---|---|---|---|---|---|---|
eval = FALSE |
× | × | × | × | × | |
include = FALSE |
× | × | × | × | × | |
echo = FALSE |
× | |||||
results = "hide" |
× | |||||
fig.show = "hide" |
× | |||||
message = FALSE |
× | |||||
warning = FALSE |
× |
如果你需要展示 R 内的数据(如 tibble),请使用 knitr::kable:
knitr::kable(
mtcars[1:5, ],
caption = "A knitr kable."
)| mpg | cyl | disp | hp | drat | wt | qsec | vs | am | gear | carb | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mazda RX4 | 21.0 | 6 | 160 | 110 | 3.90 | 2.620 | 16.46 | 0 | 1 | 4 | 4 |
| Mazda RX4 Wag | 21.0 | 6 | 160 | 110 | 3.90 | 2.875 | 17.02 | 0 | 1 | 4 | 4 |
| Datsun 710 | 22.8 | 4 | 108 | 93 | 3.85 | 2.320 | 18.61 | 1 | 1 | 4 | 1 |
| Hornet 4 Drive | 21.4 | 6 | 258 | 110 | 3.08 | 3.215 | 19.44 | 1 | 0 | 3 | 1 |
| Hornet Sportabout | 18.7 | 8 | 360 | 175 | 3.15 | 3.440 | 17.02 | 0 | 0 | 3 | 2 |
通常,文档的每次生成都从初始环境开始。这非常适合重现,但如果你有一些需要很长时间的计算,那可能会很痛苦。一种解决方案是 cache = TRUE。设置后,这将把块的输出保存到磁盘上一个特别命名的文件。在随后的运行中,knitr 将检查代码是否已更改,如果没有,它将重用缓存的结果。
{R raw_data}
rawdata <- readr::read_csv("a_very_large_file.csv")
```
{R processed_data, cache = TRUE, dependson = "raw_data"}
processed_data <- rawdata %>%
filter(!is.na(import_var)) %>%
mutate(new_variable = complicated_transformation(x, y, z))
缓存 processed_data 块意味着如果 dplyr 管道更改,它将被重新运行,但如果read_csv()调用更改,它将不会被重新运行。您可以使用 dependson块选项来避免这个问题:
{R processed_data, cache = TRUE, dependson = "raw_data"}
processed_data <- rawdata %>%
filter(!is.na(import_var)) %>%
mutate(new_variable = complicated_transformation(x, y, z))随着缓存策略变得越来越复杂,最好定期使用 knitr::clean_cache() 清除所有缓存。
对于区块输出格式上,我们可以设置一些全局选项:
knitr::opts_chunk$set(
comment = "#>",
collapse = TRUE
)
# 或是全局禁止显示代码
knitr::opts_chunk$set(
echo = FALSE
)我们还有另外一种简单的代码格式,使用 “r” 来展示一些简单的文本信息。
有时文本信息像数字一类,可能不那么容易展示,我们可能需要 format() 函数:
comma <- function(x) format(x, digits = 2, big.mark = ",")
comma(3452345)
#> [1] "3,452,345"
comma(.12358124331)
#> [1] "0.12"21.4 YAML 标头
标头有很多用处,如作为全局参数:
---
output: html_document
params:
my_class: "suv"
# 也可以用 !r 写成表达式
start: !r lubridate::ymd("2015-01-01")
---调用时使用形如 params$my_class 即可。当然你也可以在生成时追加 params 进行修改:
rmarkdown::render("fuel-economy.Rmd", params = list(my_class = "suv"))pandoc 也能生成不同样式的引文和书目(写配置到 Rmd 文件的 fontmatter 中):
bibliography: rmarkdown.bib我们可以使用许多常见的书目格式,包括 BibLaTeX,BibTeX,endnote,medline。