Chapter 22 Graphics for communication
在之前的数据分析中,我们学会了如何使用绘图作为一种强有力的理解数据的工具。当我们进行绘图可视化分析时,会为每个细节做了一个针对性的分析,方便我们快速查看和分析它们,然后分析下一个细节。在大多数分析过程中,我们会发现不一会就会产生数十或数百张 ggplot 图,而且其中大部分会立即被扔掉。
当我们已经深刻认识熟悉了数据(如 flights)后,更多要做的是将自己的理解传达给其他人。然而哪些受众人群可能不那么重视其背景知识,也不会深入研究数据。为了帮助其他人快速建立良好的数据心理模型,我们需要深入学习 ggplot2 为我们提供的一些特殊工具,因为在可展示性和优化性上,它带来的实际性进展,实在是太多了。
library(tidyverse)22.1 图外标签
试图将探索性图形转换为说明性图形时,最简单的起点是起个一眼丁真的标题。labs 的 title 配置项就是做这个的:
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(color = class)) +
geom_smooth(se = FALSE) +
labs(title = "Fuel efficiency generally decreases with engine size")
#> `geom_smooth()` using method = 'loess' and formula = 'y ~ x'%20with%20title-1.png)
标题的目的一般是总结最主要的发现。避免使用仅描述情节的标题,如 “发动机排量与燃油经济性的散点图”。
此外还有一些小标题你可能用得上:
subtitle:副标题,在标题下方以小号字体添加其他详细信息。caption:在绘图的右下角添加文本,通常用于描述数据源。
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(color = class)) +
geom_smooth(se = FALSE) +
labs(
title = "Fuel efficiency generally decreases with engine size",
subtitle = "Two seaters (sports cars) are an exception because of their light weight",
caption = "Data from fueleconomy.gov"
)
#> `geom_smooth()` using method = 'loess' and formula = 'y ~ x'%20with%20subtitle%20&%20caption-1.png)
我们也可以替换轴和图例标题。不过最好将简短的变量名称替换为更详细的描述,并包含单位:
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class)) +
geom_smooth(se = FALSE) +
labs(
x = "Engine displacement (L)",
y = "Highway fuel economy (mpg)",
colour = "Car type"
)
#> `geom_smooth()` using method = 'loess' and formula = 'y ~ x'%20with%20x%20&%20y%20&%20colour-1.png)
对于我们在建模时常常使用到的求对数等表达式,其实也是可以使用数学方程式代替文本字符串的。只需用上 quote() 即可完成转换(有点像在 markdown 里插入 Latex 公式内味,但在书写上要简单一些):
df <- tibble(
x = runif(10),
y = runif(10)
)
ggplot(df, aes(x, y)) +
geom_point() +
labs(
x = quote(sum(x[i] ^ 2, i == 1, n)),
y = quote(alpha + beta + frac(delta, theta))
)%20with%20quote()-1.png)
22.2 图内标注
除了标记图的主要组成部分之外,标记单个观测值或观测值组通常也很有用。
best_in_class <- mpg %>%
group_by(class) %>%
filter(row_number(desc(hwy)) == 1) # 筛选出行名为 1 的,即每种类型的第一个数据
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class)) +
geom_text(aes(label = model), data = best_in_class)-1.png)
事情好像并没有那么简单… 标签彼此重叠,并且与点也重叠在一起。这很难阅读。我们可以通过切换到哪个在文本后面绘制一个矩形,并将标签移动到相应点的上方来解决问题:
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class)) +
geom_label(aes(label = model), data = best_in_class, nudge_y = 2, alpha = 0.5) # geom_label() 能避免之间重叠,nudge_y 或 nudge_x 用于设置偏移量,遵循平面坐标系法则。此外减少不透明度也是不二佳选-1.png)
这有点帮助,但仔细观察,其实标签之间还是会有那么一点点重叠影响。生这种情况是因为紧凑型和次紧凑型类别中最佳汽车的高速公路里程和排量完全相同。当你无法通过对每个标签应用相同的转换来解决这些问题时,我们推荐使用 ggrepel::geom_label_repel()。它将自动调整标签,使它们不会重叠:
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class)) +
geom_point(size = 3, shape = 1, data = best_in_class) +
ggrepel::geom_label_repel(aes(label = model), data = best_in_class)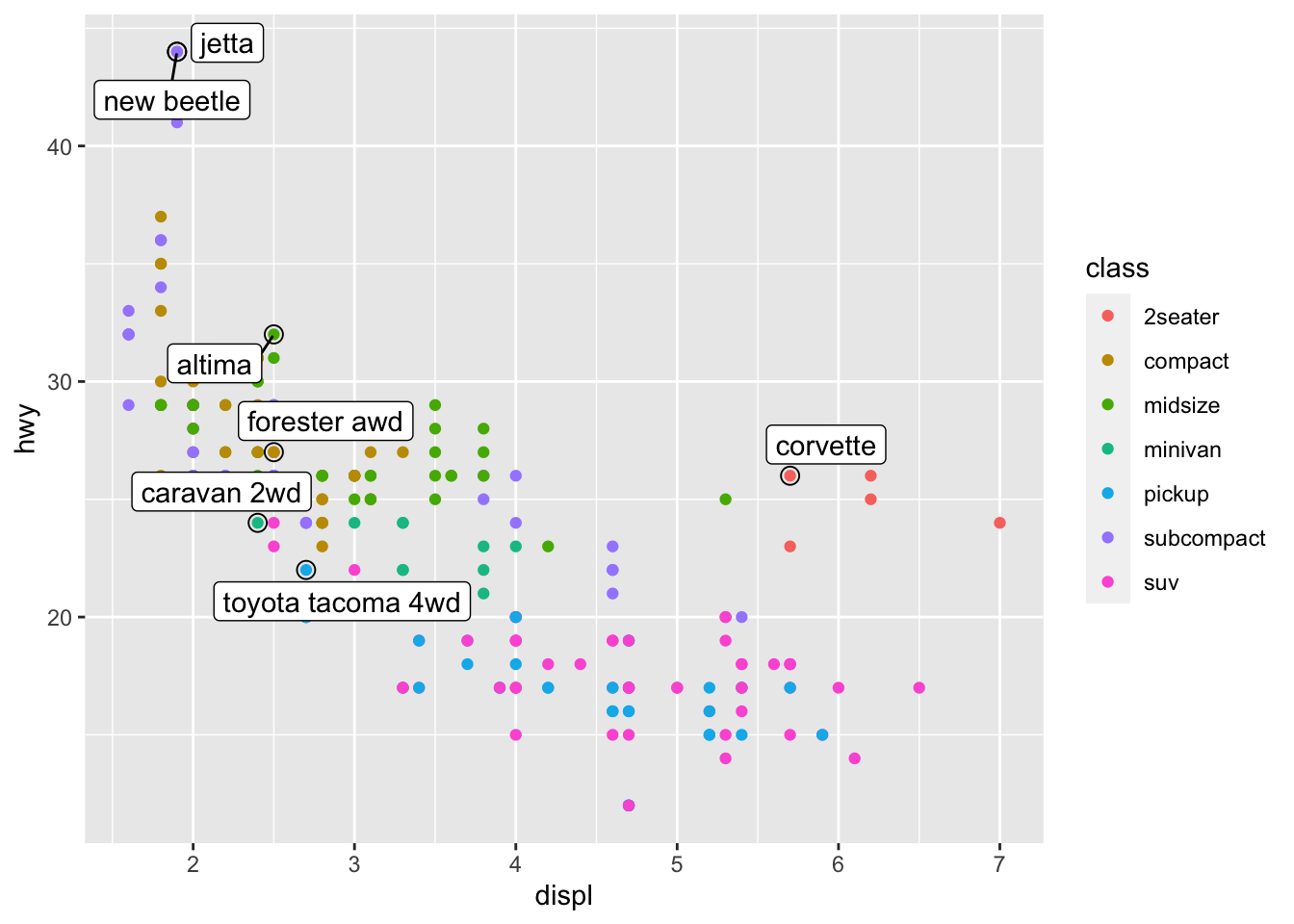
人工智障标签真好用。注意这里添加了外圈大号的空心点,以突出显示所标记的点。
此外也可以直接把图例挪到图上去做标注。这种方法好像并不优雅,但确实能解决问题而且也不算很难用:
class_avg <- mpg %>%
group_by(class) %>%
summarise(
displ = median(displ),
hwy = median(hwy)
)
ggplot(mpg, aes(displ, hwy, colour = class)) +
ggrepel::geom_label_repel(aes(label = class),
data = class_avg,
label.size = 0, # 指明标签不占位
segment.color = NA
) +
geom_point() +
theme(legend.position = "none") # 隐藏旁边的图例%20with%20theme()%20with%20legend.position-1.png)
此外我们甚至可以在图内加一些信息说明:
label <- mpg %>%
summarise(
displ = max(displ),
hwy = max(hwy),
label = "Increasing engine size is \nrelated to decreasing fuel economy." # 注意 label 在这里书写会自动添加新列
)
# 当然单纯写个 label 也可以不要那些数据
label <- tibble(
displ = Inf,
hwy = Inf,
label = "Increasing engine size is \nrelated to decreasing fuel economy."
)
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
geom_text(aes(label = label), data = label, vjust = "top", hjust = "right") # vjust 和 hjust 用于说明在竖直方向和水平方向的相对位置%20with%20label-1.png)
除了手动用换行符将内容分解为多行,我们也可以使用自动添加换行符,给定每行所需的字符数即可:
"Increasing engine size is related to decreasing fuel economy." %>%
stringr::str_wrap(width = 40) %>% # 以行宽分割并添加换行符
writeLines()
#> Increasing engine size is related to
#> decreasing fuel economy.对于刚刚的 hjust 和 vjust 参数,我们这里给出一个图👇(好耶):

“hjust” 和 “vjust” 的所有九种组合
22.3 比例尺与参考
22.3.1 比例尺
事实上在你绘制图时,ggplot 会自动为你准备好了比例尺。如:
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class))
# ggplot 会自动帮你补全成这样:
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class)) +
scale_x_continuous() +
scale_y_continuous() +
scale_colour_discrete()不过也是可以自定义的拉。
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
scale_y_continuous(breaks = seq(15, 40, by = 5))%20with%20breaks-1.png)
去掉也不是不可以:
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
scale_x_continuous(labels = NULL) +
scale_y_continuous(labels = NULL)%20with%20labels-1.png)
labels 的另一个用途是当我们的数据点相对较少并且想要突出显示观测值发生的确切位置时。如下图就清晰地它显示了每位美国总统何时开始和结束其任期:
presidential %>%
mutate(id = 33 + row_number()) %>%
ggplot(aes(start, id)) +
geom_point() +
# 点展图,以点为中心向 x 方向延伸线条,y 方向错开数据
geom_segment(aes(xend = end, yend = id)) +
scale_x_date(NULL, breaks = presidential$start, date_labels = "'%y")-1.png)
%20with%20legend.position-1.png)
%20with%20legend.position-2.png)
%20with%20legend.position-3.png)
%20with%20legend.position-4.png)