Chapter 2: Application Layer
Outline
- principles of network applications
- Web and HTTP
- Electronic mail: SMTP, POP3, IMAP
- DNS
- P2P applications
- Video streaming and content distribution networks
- Socket programming with UDP and TCP
Creating a network app
write programs that:
run on (different) end systems
communicate over network
e.g., web server software communicates with browser software
no need to write software for network-core devices:
- network-core devices(网络核心设备) do not run user applications
- applications on end systems(终端系统上的应用程序) allows for rapid app development, propagation(传播)
结构上:
- client-server 服务器与客户端
- peer-to-peer (P2P) 端对端
Client-server architecture
server:
- always-on host(不间断主机)
- permanent(永久) IP address
- data centers for scaling(拓展)
clients:
- communicate with server
- may be intermittently(间歇性的) connected
- may have dynamic IP addresses(动态 IP)
- do not communicate directly with each other
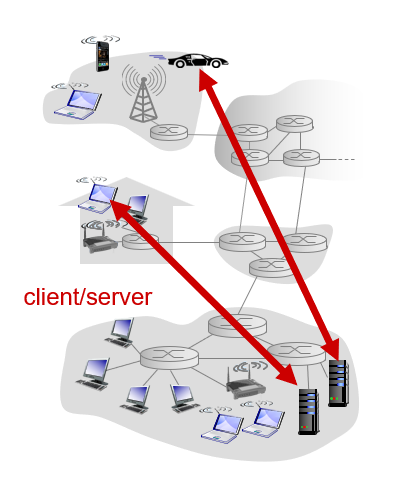
P2P architecture
no always-on server
arbitrary(任意的) end systems directly communicate
peers(对等体) request service from other peers, provide service in return to other peers
self scalability(自我弹性) – new peers bring new service capacity(容量), as well as new service demands(需求)
peers are intermittently(间歇性) connected and change IP addresses
complex(复杂的) management
Processes communicating
- client process: process that initiates communication
- server process: process that waits to be contacted
Applications with P2P architectures have client processes & server processes
Sockets
用大白话解释什么是 Socket - 知乎 (zhihu.com)
套接字(socket)是一个抽象层,应用程序可以通过它发送或接收数据,可对其进行像对文件一样的打开、读写和关闭等操作。套接字允许应用程序将 I/O 插入到网络中,并与网络中的其他应用程序进行通信。网络套接字是 IP 地址与端口的组合。
我们将一个小区比作一台计算机,一台计算机里面跑了很多程序,怎么区分程序呢,用的是端口,就好像小区用门牌号区分每一户人家一样。手机送到小明家了,怎么进去呢?从大门进啊,怎么找到大门呢?门牌号呀。不就相当于从互联网来的数据找到接收端计算机后再根据端口判断应该给哪一个程序一样吗。小明家的入口就可以用小区地址+门牌号进行唯一表示,那么同样的道理,程序也可以用 IP+端口号进行唯一标识。那么这个程序的入口就被称作 Socket。
socket analogous(很相似的) to door:
- sending process shoves(推送) message out door
- sending process relies on transport infrastructure(基础设施) on other side of door to deliver message to socket at receiving process
Addressing processes
To receive messages, process must have identifier.
identifier includes both IP address and port numbers associated with process on host.
What transport service does an app need?
data integrity(数据完整性)
- some apps (e.g., file transfer, web transactions) require 100% reliable data transfer
- other apps (e.g., audio) can tolerate(容忍,允许) some loss
timing(时效性,即时性)
- some apps (e.g., Internet telephony(网络电话), interactive games) require low delay to be “effective”
throughput(吞吐率)
- some apps (e.g., multimedia) require minimum amount of throughput to be “effective”
- other apps (“elastic apps”,弹性应用) make use of whatever throughput they get
security(安全性)
- encryption, data integrity(数据完整性)
Internet transport protocols(协议) services
TCP service:
- reliable transport between sending and receiving process
- flow control(流量控制): sender won’t overwhelm(溢出) receiver
- congestion control(拥塞控制): throttle(限制,掐死) sender when network overloaded
- does not provide: timing, minimum throughput guarantee, security
- connection-oriented(面向连接): setup required between client and server processes
UDP service:
- unreliable data transfer between sending and receiving process
- does not provide: reliability, flow control, congestion control, timing, throughput guarantee, security, or connection setup
TCP 和 UDP 的区别 - 知乎 (zhihu.com)
TCP/IP 协议是一个协议簇。里面包括很多协议的,UDP 只是其中的一个,之所以命名为 TCP/IP 协议,因为 TCP、IP 协议是两个很重要的协议,就用他两命名了。
TCP/IP 协议集包括应用层,传输层,网络层,网络访问层。
TCP(Transmission Control Protocol,传输控制协议)
TCP 是面向连接的协议,也就是说,在收发数据前,必须和对方建立可靠的连接。一个 TCP 连接必须要经过三次“对话”才能建立起来。
UDP(User Data Protocol,用户数据报协议)
1、UDP 是一个非连接的协议,传输数据之前源端和终端不建立连接,当它想传送时就简单地去抓取来自应用程序的数据,并尽可能快地把它扔到网络上。在发送端,UDP 传送数据的速度仅仅是受应用程序生成数据的速度、计算机的能力和传输带宽的限制;在接收端,UDP 把每个消息段放在队列中,应用程序每次从队列中读一个消息段。
2、由于传输数据不建立连接,因此也就不需要维护连接状态,包括收发状态等,因此一台服务机可同时向多个客户机传输相同的消息。
3、UDP 信息包的标题很短,只有 8 个字节,相对于 TCP 的 20 个字节信息包的额外开销很小。
4、吞吐量不受拥挤控制算法的调节,只受应用软件生成数据的速率、传输带宽、源端和终端主机性能的限制。
5、UDP 使用尽最大努力交付,即不保证可靠交付,因此主机不需要维持复杂的链接状态表(这里面有许多参数)。
6、UDP 是面向报文的。发送方的 UDP 对应用程序交下来的报文,在添加首部后就向下交付给 IP 层。既不拆分,也不合并,而是保留这些报文的边界,因此,应用程序需要选择合适的报文大小。
Securing TCP and SSL
TCP & UDP 存在的问题:
- no encryption
- cleartext passwds(明文密码) sent into socket traverse(通过) Internet in cleartext
SSL:
- provides encrypted TCP connection
- data integrity(数据完整性)
- end-point authentication(身份验证)
此外注意:
SSL is at app layer(位于应用层): apps use SSL libraries, that “talk” to TCP
SSL socket API: cleartext passwords sent into socket traverse Internet encrypted
Web and HTTP
HTTP 的发展 - HTTP | MDN (mozilla.org)
HTTP(HyperText Transfer Protocol)是万维网(World Wide Web)的基础协议。自 Tim Berners-Lee 博士和他的团队在 1989-1991 年间创造出它以来,HTTP 已经发生了太多的变化,在保持协议简单性的同时,不断扩展其灵活性。如今,HTTP 已经从一个只在实验室之间交换文件的早期协议进化到了可以传输图片,高分辨率视频和 3D 效果的现代复杂互联网协议。
万维网的发明
1989 年,当时在 CERN 工作的 Tim Berners-Lee 博士写了一份关于建立一个通过网络传输超文本系统的报告。这个系统起初被命名为 Mesh,在随后的 1990 年项目实施期间被更名为万维网(World Wide Web)。它在现有的 TCP 和 IP 协议基础之上建立,由四个部分组成:
- 一个用来表示超文本文档的文本格式,超文本标记语言(HTML)。
- 一个用来交换超文本文档的简单协议,超文本传输协议(HTTP)。
- 一个显示(以及编辑)超文本文档的客户端,即网络浏览器。第一个网络浏览器被称为 WorldWideWeb。
- 一个服务器用于提供可访问的文档,即 httpd 的前身。
HTTP 在应用的早期阶段非常简单,后来被称为 HTTP/0.9,有时也叫做单行(one-line)协议。
HTTP/0.9——单行协议
最初版本的 HTTP 协议并没有版本号,后来它的版本号被定位在 0.9 以区分后来的版本。HTTP/0.9 极其简单:请求由单行指令构成,以唯一可用方法
GET开头,其后跟目标资源的路径(一旦连接到服务器,协议、服务器、端口号这些都不是必须的)。GET /mypage.html响应也极其简单的:只包含响应文档本身。
<HTML> 这是一个非常简单的 HTML 页面 </HTML>跟后来的版本不同,HTTP/0.9 的响应内容并不包含 HTTP 头。这意味着只有 HTML 文件可以传送,无法传输其他类型的文件。也没有状态码或错误代码。一旦出现问题,一个特殊的包含问题描述信息的 HTML 文件将被发回,供人们查看。
HTTP/1.0——构建可扩展性
由于 HTTP/0.9 协议的应用十分有限,浏览器和服务器迅速扩展内容使其用途更广:
- 协议版本信息现在会随着每个请求发送(
HTTP/1.0被追加到了GET行)。- 状态码会在响应开始时发送,使浏览器能了解请求执行成功或失败,并相应调整行为(如更新或使用本地缓存)。
- 引入了 HTTP 标头的概念,无论是对于请求还是响应,允许传输元数据,使协议变得非常灵活,更具扩展性。
- 在新 HTTP 标头的帮助下,具备了传输除纯文本 HTML 文件以外其他类型文档的能力(凭借
Content-Type标头)。一个典型的请求看起来就像这样:
GET /mypage.html HTTP/1.0 User-Agent: NCSA_Mosaic/2.0 (Windows 3.1) 200 OK Date: Tue, 15 Nov 1994 08:12:31 GMT Server: CERN/3.0 libwww/2.17 Content-Type: text/html <HTML> 一个包含图片的页面 <IMG SRC="/myimage.gif"> </HTML>接下来是第二个连接,请求获取图片(并具有相同的响应):
GET /myimage.gif HTTP/1.0 User-Agent: NCSA_Mosaic/2.0 (Windows 3.1) 200 OK Date: Tue, 15 Nov 1994 08:12:32 GMT Server: CERN/3.0 libwww/2.17 Content-Type: text/gif (这里是图片内容)在 1991-1995 年,这些新扩展并没有被引入到标准中以促进协助工作,而仅仅作为一种尝试。服务器和浏览器添加这些新扩展功能,但出现了大量的互操作问题。直到 1996 年 11 月,为了解决这些问题,一份新文档(RFC 1945)被发表出来,用以描述如何操作实践这些新扩展功能。文档 RFC 1945 定义了 HTTP/1.0,但它是狭义的,并不是官方标准。
HTTP/1.1——标准化的协议
HTTP/1.0 多种不同的实现方式在实际运用中显得有些混乱。自 1995 年开始,即 HTTP/1.0 文档发布的下一年,就开始修订 HTTP 的第一个标准化版本。在 1997 年初,HTTP1.1 标准发布,就在 HTTP/1.0 发布的几个月后。
HTTP/1.1 消除了大量歧义内容并引入了多项改进:
- 连接可以复用,节省了多次打开 TCP 连接加载网页文档资源的时间。
- 增加管线化技术,允许在第一个应答被完全发送之前就发送第二个请求,以降低通信延迟。
- 支持响应分块。
- 引入额外的缓存控制机制。
- 引入内容协商机制,包括语言、编码、类型等。并允许客户端和服务器之间约定以最合适的内容进行交换。
- 凭借
Host标头,能够使不同域名配置在同一个 IP 地址的服务器上。一个典型的请求流程,所有请求都通过一个连接实现,看起来就像这样:
GET /en-US/docs/Glossary/Simple_header HTTP/1.1 Host: developer.mozilla.org User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: en-US,en;q=0.5 Accept-Encoding: gzip, deflate, br Referer: https://developer.mozilla.org/en-US/docs/Glossary/Simple_header 200 OK Connection: Keep-Alive Content-Encoding: gzip Content-Type: text/html; charset=utf-8 Date: Wed, 20 Jul 2016 10:55:30 GMT Etag: "547fa7e369ef56031dd3bff2ace9fc0832eb251a" Keep-Alive: timeout=5, max=1000 Last-Modified: Tue, 19 Jul 2016 00:59:33 GMT Server: Apache Transfer-Encoding: chunked Vary: Cookie, Accept-Encoding (content) GET /static/img/header-background.png HTTP/1.1 Host: developer.mozilla.org User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0 Accept: */* Accept-Language: en-US,en;q=0.5 Accept-Encoding: gzip, deflate, br Referer: https://developer.mozilla.org/en-US/docs/Glossary/Simple_header 200 OK Age: 9578461 Cache-Control: public, max-age=315360000 Connection: keep-alive Content-Length: 3077 Content-Type: image/png Date: Thu, 31 Mar 2016 13:34:46 GMT Last-Modified: Wed, 21 Oct 2015 18:27:50 GMT Server: Apache (image content of 3077 bytes)HTTP/1.1 在 1997 年 1 月以 RFC 2068 文件发布。
由于 HTTP 协议的可扩展性使得创建新的头部和方法是很容易的。即使 HTTP/1.1 协议进行过两次修订,RFC 2616 发布于 1999 年 6 月,而另外两个文档 RFC 7230-RFC 7235 发布于 2014 年 6 月(在 HTTP/2 发布之前)。HTTP/1.1 协议已经稳定使用超过 15 年了。
HTTP overview
HTTP: hypertext(超文本) transfer protocol
Web’s application layer protocol
client/server model
- client: browser that requests, receives, (using HTTP protocol) and “displays” Web objects
- server: Web server sends (using HTTP protocol) objects in response to requests
HTTP request message: ASCII (human-readable format)
Uploading form input
POST method:
- web page often includes form input
- input is uploaded to server in entity(实体) body
URL method:
uses GET method
input is uploaded in URL field of request line:如
www.somesite.com/animalsearch?monkeys&banana
Method types
HTTP/1.0:
- GET
- POST
- HEAD:asks server to leave requested object out of response
HTTP/1.1:
- GET
- POST
- HEAD
- PUT:uploads file in entity body to path specified in URL field
- DELETE:deletes file specified in the URL field
HTTP response status codes(HTTP 响应状态码)
status code appears in 1st line in server-to-client response message.
HTTP 响应状态码 - HTTP | MDN (mozilla.org)
HTTP 响应状态码用来表明特定 HTTP 请求是否成功完成。 响应被归为以下五大类:
**备注:**如果您收到的响应不在 此列表 中,则它为非标准响应,可能是服务器软件的自定义响应。
HTTP response status codes - PlayFab | Microsoft Learn
常见的相应状态码:
HTTP status code General description 100 Continue: Returned on HEAD requests 200 OK: Returned for all successful requests. May indicate partial success for bulk APIs. 201 Created: Request was successful and resource was created. 202 Accepted: Request was successful, processing will continue asynchronously. 204 No Content: API successful, but there is no response to be returned from the API. 301 Moved Permanently: requested object moved, new location specified later in this msg (Location:) 400 Bad Request: Parameters in request where invalid or request payload structure was invalid. Do not retry. 401 Unauthorized: Caller is not authorized to either call the specific API or perform the action requested. Do not retry. 403 Forbidden: Caller is not allowed access. Do not retry. 404 Not Found: API does not exist. Do not retry. 408 Request Timeout: The request took too long to be sent to the server. Okay to retry using exponential backoff pattern. 409 Conflict: A concurrency error occurred between two API calls. Okay to retry using exponential backoff pattern. 413 Payload Too Large: The request is larger than the server is allowed to handle. Do not retry. If unexpected, contact support. 414 URI Too Long: The URI in the request is longer than the server is allowed to handle. Do not retry. 429 Too Many Requests: API calls are being rate limited. Pause and then retry request, check if API returned “Retry-After” header or retryAfter in JSON response for delay needed. 500 Internal Server Error: An error occurred on the PlayFab server. Okay to retry, contact support if problem persists. 501 Not Implemented: The API called has not been implemented yet. Do not retry. 502 Bad Gateway: PlayFab API servers are not available to process the request. Pause and then retry request using exponential backoff pattern. 503 Service Unavailable: PlayFab API servers are not available to process the request. Pause and then retry request using exponential backoff pattern. 504 Gateway Timeout: PlayFab API servers are not available to process the request. Pause and then retry request. 505 HTTP Version Not Supported
User-server state: cookies
many Web sites use cookies
four components:
- cookie header line of HTTP response message
- cookie header line in next HTTP request message
- cookie file kept on user’s host, managed by user’s browser
- back-end database at Web site
what cookies can be used for:
- authorization
- shopping carts(购物车,也代指其他需要存储的东西)
- recommendations
- user session state (Web e-mail)
Web caches (proxy server)
user sets browser: Web accesses via cache
browser sends all HTTP requests to cache
object in cache: cache returns object else cache requests object from origin server, then returns object to client
Web 缓存(也称为代理服务器)是广泛用于提高 Web 页面加载速度和减轻网络流量压力的技术。它的工作方式是在用户和 Web 服务器之间放置一个位于网络边缘的服务器,该服务器存储先前获取的 Web 页面的副本,以便当后续用户请求相同页面时,可以直接返回本地存储的副本,而不必重新从源服务器下载。这样,用户就可以更快地加载页面,并且减轻了源服务器的压力。
Web 缓存可以根据不同的应用场景进行配置,例如在企业内部网络中设置私有 Web 缓存来提高内部网站的访问速度,或在 Internet 网络边缘设置公共 Web 缓存来减轻互联网上的流量压力。此外,Web 缓存还可以通过缓存一些常用的 JavaScript 和 CSS 文件等静态资源,来进一步提高页面加载速度。
需要注意的是,Web 缓存不适用于动态生成的 Web 页面或需要个性化处理的页面,因为这些页面的内容是根据用户请求动态生成的,所以不可能事先缓存下来。此外,一些受保护的 Web 页面(如登录页)也不能缓存,因为每个用户的页面内容都是不同的,不适合缓存下来供其他用户使用。
Conditional GET
Conditional GET 是一个 HTTP 协议的特性,可以在客户端像服务器发起请求时,通过发送 HTTP 头部中的条件标识,让服务器判断资源是否发生了变化,如果资源未发生变化,服务器可以选择不返回资源实体,而是返回 304 Not Modified 状态码,从而节省网络带宽和服务器资源。
使用条件 GET 时,客户端发送的请求中会包含 If-Modified-Since、If-Unmodified-Since、If-Match、If-None-Match 等条件标识,这些条件标识指定了客户端请求的资源应该满足的条件。当服务器对客户端的请求进行处理时,会根据这些条件是否满足来决定是否返回实际的资源,或者只返回 304 状态码。
条件 GET 可以提高网络传输效率和响应速度,因为服务器避免了重复发送已经有缓存的资源,从而降低了网络带宽的消耗。
Electronic Mail
Introduction to Electronic Mail - GeeksforGeeks
Electronic mail, commonly known as email, is a method of exchanging messages over the internet.
Here are the basics of email:
- An email address: This is a unique identifier for each user, typically in the format of
name@domain.com.- An email client: This is a software program used to send, receive and manage emails, such as Gmail, Outlook, or Apple Mail.
- An email server: This is a computer system responsible for storing and forwarding emails to their intended recipients.
SMTP (Simple Mail Transfer Protocol)、POP3 (Post Office Protocol Version 3) 和 IMAP (Internet Message Access Protocol) 都是在互联网上传输邮件的协议。
SMTP
SMTP (Simple Mail Transfer Protocol [RFC 2821]): 协议不负责接收邮件,在邮件传递过程中,它只负责将邮件从发送者的邮件服务器传递到接收者的邮件服务器。SMTP 协议发送邮件的过程通常分为以下步骤:
- 发送方邮件客户端(如 Outlook 等)向发送方邮件服务器发送邮件。
- 发送方邮件服务器将邮件发送给接收方邮件服务器,通过 SMTP 协议与接收方邮件服务器通信,询问是否可以接收该邮件。
- 接收方邮件服务器回复确认,发送方邮件服务器将邮件发送给接收方邮件服务器。
- 接收方邮件服务器接收到邮件并存储下来,接收方在自己的邮件客户端中查看邮件。
SMTP 协议的工作原理如下:
连接建立(SMTP connection opened):发送方邮件服务器与接收方邮件服务器建立 TCP 连接(25 号端口);握手:发送方发送 EHLO 命令告诉接收方客户端自己的域名和所支持的命令,接收方回复 250 OK 表示可以通信。
发送邮件数据(Email data transferred):发送方向接收方发送邮件数据,包括邮件头和邮件正文。
Mail Transfer Agent (MTA): 在邮件传输过程中实际传送邮件的程序或服务。MTA 会负责从发件人的 SMTP 客户端接收邮件并将其传递给相应的收件人的 SMTP 服务器。MTA 还可以处理邮件发送过程中的错误或问题,例如无法传递邮件或邮件被拒绝等情况。常见的 MTA 软件包括 Sendmail、Postfix 和 Qmail 等。
What is the Simple Mail Transfer Protocol (SMTP)? | Cloudflare
The server runs a program called a Mail Transfer Agent (MTA). The MTA checks the domain of the recipient's email address, and if it differs from the sender's, it queries the Domain Name System (DNS) to find the recipient's IP address. This is like a post office looking up a mail recipient's zip code.
断开连接(Connection closed):发送方发送 QUIT 命令告诉接收方已经完成发送,接收方回复 221 表示连接已断开。
POP3 是一种用于接收电子邮件的协议。当您使用 POP3 协议从邮件服务器下载邮件时,邮件服务器就会将邮件传送到您的邮件客户端中,并从服务器上删除邮件。
IMAP 是另一种用于接收电子邮件的协议,它与 POP3 不同的是,它允许您在邮件服务器上保留邮件的副本,可以在多个设备之间同步邮件。这样,当您在一个设备上修改或删除邮件时,在其他设备上也可以看到这些修改。
What is the Simple Mail Transfer Protocol (SMTP)? | Cloudflare
What are SMTP commands?
SMTP commands are predefined text-based instructions that tell a client or server what to do and how to handle any accompanying data. Think of them as buttons the client can press to get the server to accept data correctly.
HELO/EHLO: These commands say "Hello" and start off the SMTP connection between client and server. "HELO" is the basic version of this command; "EHLO" is for a specialized type of SMTP.
MAIL FROM: This tells the server who is sending the email. If Alice were trying to email her friend Bob, a client might send "MAIL FROM:alice@example.com".
RCPT TO: This command is for listing the email's recipients. A client can send this command multiple times if there are multiple recipients. In the example above, Alice's email client would send "RCPT TO:bob@example.com".
DATA: This precedes the content of the email.It obeys RFC 822: standard for text message format. Like:
DATA Date: Mon, 4 April 2022 From: Alice alice@example.com Subject: Eggs benedict casserole To: Bob bob@example.com Hi Bob, I will bring the eggs benedict casserole recipe on Friday. -Alice .Pay attention to line 6 and line 10.
RSET: This command resets the connection, removing all previously transferred information without closing the SMTP connection.RSETis used if the client sent incorrect information.QUIT: This ends the connection.
- SMTP uses persistent(持续的,可持续的) connections
- SMTP requires message (header & body) to be in 7-bit ASCII
- SMTP server uses CRLF.CRLF(就是指一个点) to determine end of message
comparison with HTTP:
- HTTP: pull
- SMTP: push
POP
POP (Post Office Protocol [RFC 1939]): authorization, download.
而 POP3 是一种用于接收电子邮件的协议。当您使用 POP3 协议从邮件服务器下载邮件时,邮件服务器就会将邮件传送到您的邮件客户端中,并从服务器上删除邮件。
IMAP
IMAP: Internet Mail Access Protocol [RFC 1730]: more features, including manipulation of stored messages on server.
IMAP 是另一种用于接收电子邮件的协议,它与 POP3 不同的是,它允许您在邮件服务器上保留邮件的副本(§keeps all messages in one place: at server),可以在多个设备之间同步邮件。这样,当您在一个设备上修改或删除邮件时,在其他设备上也可以看到这些修改。此外还有 allows user to organize messages in folders。
DNS
什么是 DNS
DNS 出现及演化
网络出现的早期 是使用 IP 地址通讯的,那时就几台主机通讯。但是随着接入网络主机的增多,这种数字标识的地址非常不便于记忆,UNIX 上就出现了建立一个叫做 hosts 的文件 (Linux 和 Windows 也继承保留了这个文件)。这个文件中记录这主机名称和 IP 地址的对应表。这样只要输入主机名称,系统就会去加载 hosts 文件并查找对应关系,找到对应的 IP,就可以访问这个 IP 的主机了。
但是后来主机太多了,无法保证所有人都能拿到统一的最新的 hosts 文件,就出现了在文件服务器上集中存放 hosts 文件,以供下载使用。互联网规模进一步扩大,这种方式也不堪负重,而且把所有地址解析记录形成的文件都同步到所有的客户机似乎也不是一个好办法。这时 DNS 系统出现了,随着解析规模的继续扩大,DNS 系统也在不断的演化,直到现今的多层架构体系。
DNS 概括
DNS(Domain Name System,域名系统),因特网上作为域名和 IP 地址互相映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的 IP 数串。通过主机名,最终得到该主机对应的 IP 地址的过程叫做域名解析(或主机名解析)。DNS 协议运行在 UDP 协议之上,使用端口号 53。
DNS 的分布数据库是以域名为索引的,每个域名实际上就是一棵很大的逆向树中路径,这棵逆向树称为域名空间(domain name space),如下图所示树的最大深度不得超过 127 层,树中每个节点都有一个可以长达 63 个字符的文本标号。
DNS 的作用
- 正向解析:根据主机名称(域名)查找对应的 IP 地址
- 反向解析:根据 IP 地址查找对应的主机域名
DNS 系统的分布式数据结构:
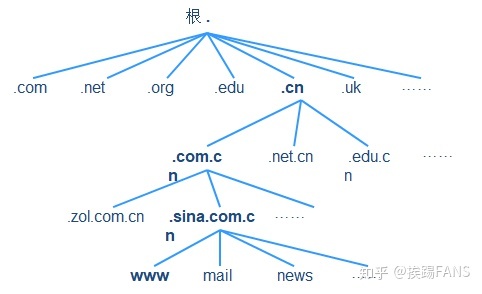
DNS 相关服务器及实现
什么是 DNS-DNS 如何工作-权威性 DNS 服务器 | Cloudflare 中国官网 | Cloudflare
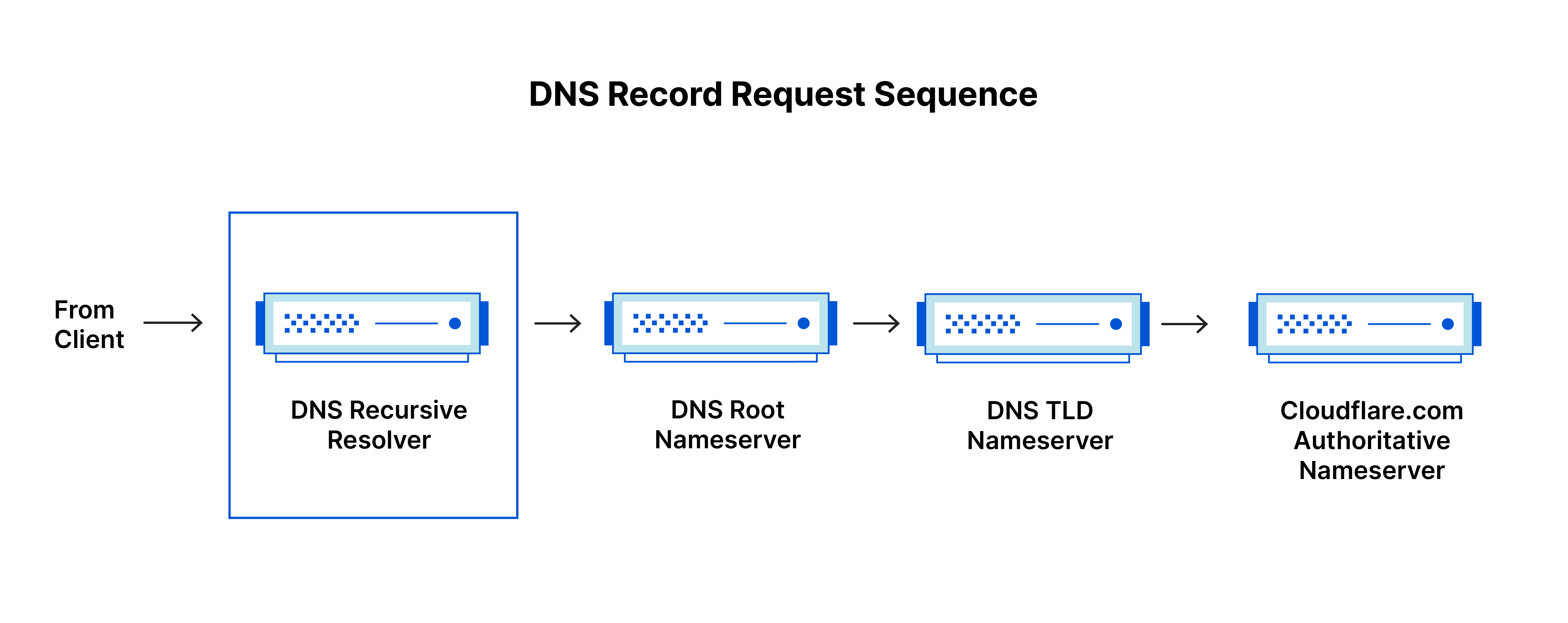
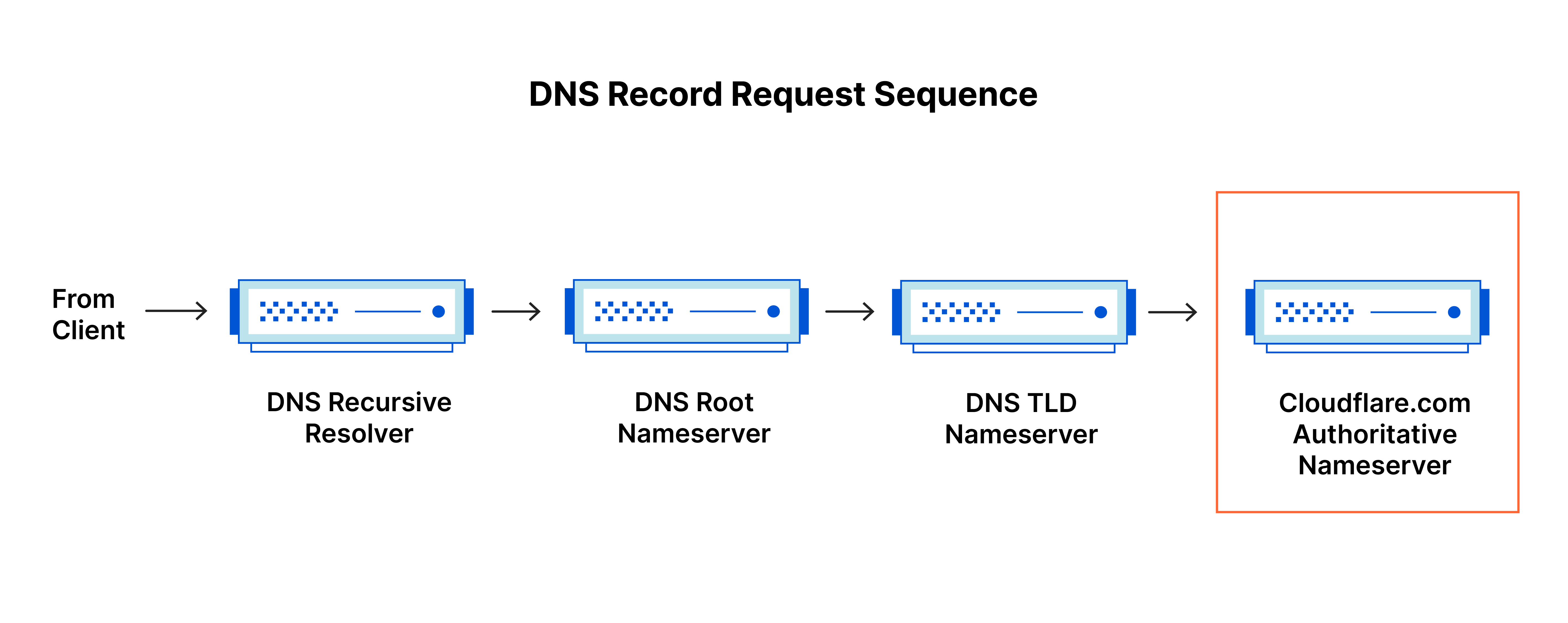
加载网页涉及 4 个 DNS 服务器
- DNS 解析器:该解析器可被视为被要求去图书馆的某个地方查找特定图书的图书馆员。DNS 解析器是一种服务器,旨在通过 Web 浏览器等应用程序接收客户端计算机的查询。然后,解析器一般负责发出其他请求,以便满足客户端的 DNS 查询。
- 根域名服务器:根域名服务器是将人类可读的主机名转换(解析)为 IP 地址的第一步。可将其视为指向不同书架的图书馆中的索引 - 一般其作为对其他更具体位置的引用。
- TLD 名称服务器:顶级域名服务器(TLD,Top-level domain)可看做是图书馆中一个特殊的书架。这个域名服务器是搜索特定 IP 地址的下一步,其上托管了主机名的最后一部分(例如,在 example.com 中,TLD 服务器为 “com”)。
- 权威性域名服务器:可将这个最终域名服务器视为书架上的字典,其中特定名称可被转换成其定义。权威性域名服务器是域名服务器查询中的最后一站。如果权威性域名服务器能够访问请求的记录,则其会将已请求主机名的 IP 地址返回到发出初始请求的 DNS 解析器(图书管理员)。
权威性 DNS 服务器与递归 DNS 解析器之间的区别是什么?
这两个概念都是指 DNS 基础设施不可或缺的服务器(服务器组),但各自担当不同的角色,并且位于 DNS 查询管道内的不同位置。考虑二者差异的一种方式是,递归解析器位于 DNS 查询的开头,而权威性域名服务器位于末尾。
递归 DNS 解析器
递归解析器是一种计算机,其响应来自客户端的递归请求并花时间追踪 DNS 记录。为执行此操作,其发出一系列请求,直至到达用于所请求的记录的权威性 DNS 域名服务器为止(或者超时,或者如果未找到记录,则返回错误)。幸运的是,递归 DNS 解析器并不总是需要发出多个请求才能追踪响应客户端所需的记录;缓存是一种数据持久性过程,可通过在 DNS 查找中更早地服务于所请求的资源记录来为所需的请求提供捷径。
权威性 DNS 服务器
简言之,权威性 DNS 服务器是实际持有并负责 DNS 资源记录的服务器。这是位于 DNS 查找链底部的服务器,其将使用所查询的资源记录进行响应,从而最终允许发出请求的 Web 浏览器达到访问网站或其他 Web 资源所需的 IP 地址。权威性域名服务器从自身数据满足查询需求,无需查询其他来源,因为这是某些 DNS 记录的最终真实来源。
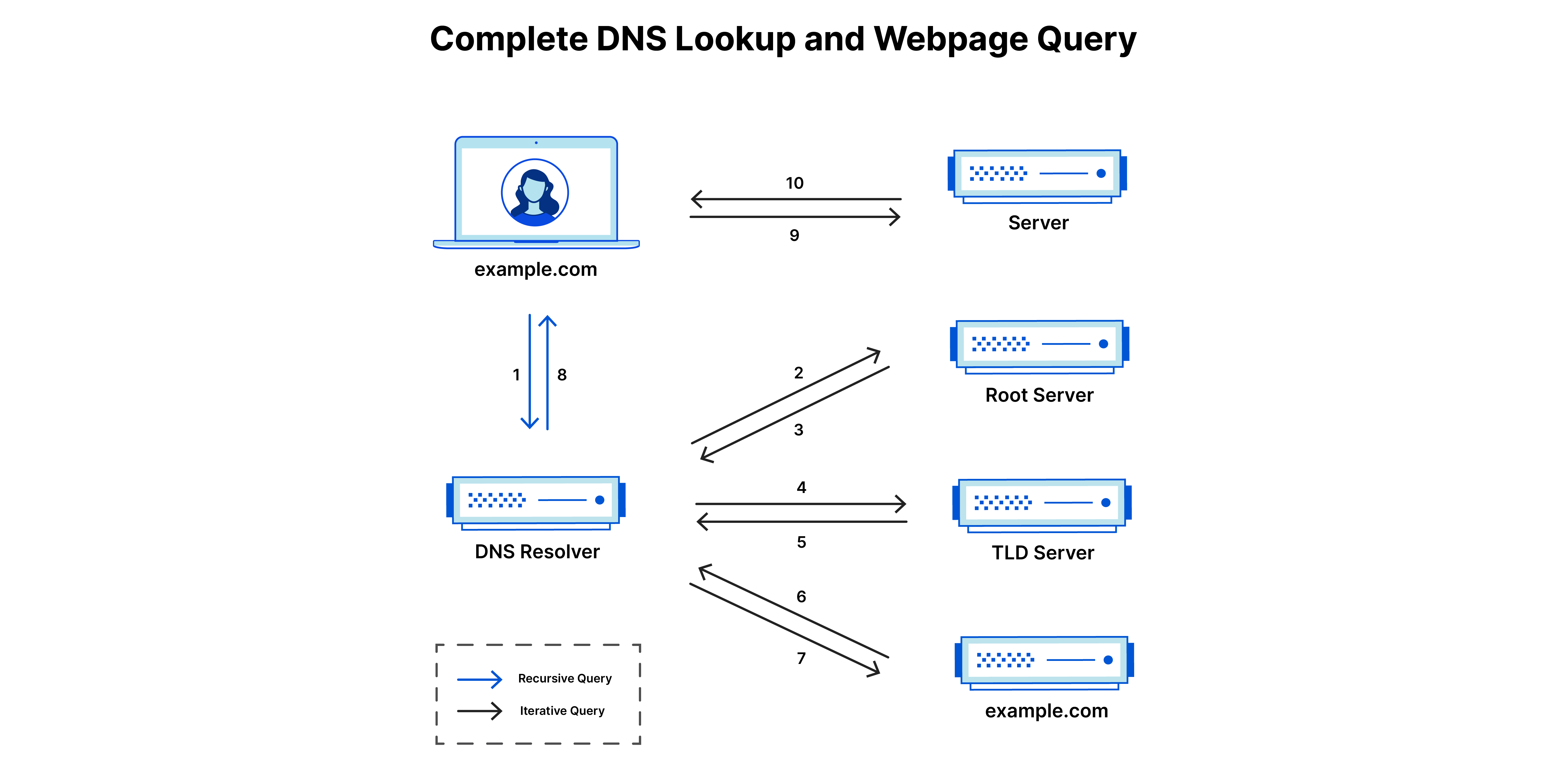
DNS 查找的 8 个步骤
用户在 Web 浏览器中键入 “example.com”,查询传输到 Internet 中,并被 DNS 递归解析器接收。
接着,解析器查询 DNS 根域名服务器(.)。
然后,根服务器使用存储其域信息的顶级域(TLD)DNS 服务器(例如 .com 或 .net)的地址响应该解析器。在搜索 example.com 时,我们的请求指向 .com TLD。
然后,解析器向 .com TLD 发出请求。
TLD 服务器随后使用该域的域名服务器 example.com 的 IP 地址进行响应。
最后,递归解析器将查询发送到域的域名服务器。
example.com 的 IP 地址而后从域名服务器返回解析器。
然后 DNS 解析器使用最初请求的域的 IP 地址响应 Web 浏览器。
DNS 查找的这 8 个步骤返回 example.com 的 IP 地址后,浏览器便能发出对该网页的请求:
浏览器向该 IP 地址发出HTTP 请求。
位于该 IP 的服务器返回将在浏览器中呈现的网页(第 10 步)。
什么是 DNS 高速缓存?DNS 高速缓存发生在哪里?
缓存的目的是将数据临时存储在某个位置,从而提高数据请求的性能和可靠性。DNS 高速缓存涉及将数据存储在更靠近请求客户端的位置,以便能够更早地解析 DNS 查询,并且能够避免在 DNS 查找链中进一步向下的额外查询,从而缩短加载时间并减少带宽/CPU 消耗。DNS 数据可缓存到各种不同的位置上,每个位置均将存储 DNS 记录并保存由生存时间(TTL,time to live)决定的一段时间。
浏览器 DNS 缓存
现代 Web 浏览器设计为默认将 DNS 记录缓存一段时间。目的很明显;越靠近 Web 浏览器进行 DNS 缓存,为检查缓存并向 IP 地址发出正确请求而必须采取的处理步骤就越少。发出对 DNS 记录的请求时,浏览器缓存是针对所请求的记录而检查的第一个位置。
在 Chrome 浏览器中,您可以转到 chrome://net-internals/#dns 查看 DNS 缓存的状态。
操作系统(OS)级 DNS 缓存
操作系统级 DNS 解析器是 DNS 查询离开您计算机前的第二站,也是本地最后一站。操作系统内旨在处理此查询的过程通常称为“存根解析器”或 DNS 客户端。当存根解析器获取来自某个应用程序的请求时,其首先检查自己的缓存,以便查看是否有此记录。如果没有,则将本地网络外部的 DNS 查询(设置了递归标记)发送到 Internet 服务提供商(ISP)内部的 DNS 递归解析器。
与先前所有步骤一样,当 ISP 内的递归解析器收到 DNS 查询时,其还将查看所请求的主机到 IP 地址转换是否已经存储在其本地持久性层中。
根据其缓存中具有的记录类型,递归解析器还具有其他功能:
DNS Records
DNS 记录(又名区域文件)是位于权威 DNS 服务器中的指令,提供一个域的相关信息,包括哪些 IP 地址与该域关联,以及如何处理对该域的请求。这些记录由一系列以所谓的 DNS 语法编写的文本文件组成。DNS 语法是用作命令的字符串,这些命令告诉 DNS 服务器执行什么操作。此外,所有 DNS 记录都有一个 “TTL”,其代表生存时间,指示 DNS 服务器多久刷新一次该记录。
最常见的 DNS 记录有:
- A 记录:保存域的 IP 地址的记录。
- AAAA 记录:包含域的 IPv6 地址的记录(与 A 记录相反,A 记录列出的是 IPv4 地址)。
- CNAME 记录:将一个域或子域转发到另一个域,不提供 IP 地址。
- MX 记录:将邮件定向到电子邮件服务器。
- TXT 记录:可让管理员在记录中存储文本注释。这些记录通常用于电子邮件安全。
- NS 记录:存储 DNS 条目的名称服务器。
- SOA 记录:存储域的管理信息。
- SRV 记录:指定用于特定服务的端口。
- PTR 记录:在反向查询中提供域名。
P2P Applications(不重要)
Pure P2P architecture(体系结构)
- no always-on server
- arbitrary(任意的) end systems directly communicate(直接通信)
- peers(原叫同龄人,这里指对等端) are intermittently connected and change IP addresses
Video streaming and content distribution networks (CDNs)(不重要)
Video traffic
Video traffic: major consumer of Internet bandwidth
solution: distributed, application-level infrastructure(分布式应用程序级基础架构)
CBR(恒定比特率)是指视频编码时采用固定的比特率来保证视频的一致性和稳定性,不论视频场景中的运动、细节、色彩变化等情况如何。因此,CBR 编码方式适用于要求视频画质和大小都相同的场合,比如直播、视频会议等。
VBR(可变比特率)是指视频编码时采用动态的比特率来实现更高的压缩效率和更好的视觉质量,它根据不同的场景自适应地改变编码比特率,达到了优化视频质量和压缩比的平衡。因此,VBR 编码方式适用于对视频质量要求高,但视频大小不是首要考虑因素的场合,比如电影、高清视频等。
如:
- MPEG 1 (CD-ROM) 1.5 Mbps
- MPEG 2 (DVD) 3-6 Mbps
- MPEG 4 (often used in Internet, < 1 Mbps)
Streaming multimedia: DASH
DASH(Dynamic, Adaptive Streaming over HTTP)即动态自适应流式传输协议,是一种通过互联网以 HTTP 协议传输音视频内容的方法。DASH 协议允许在不同的网络环境下自动调整音视频的码率和分辨率,以保证用户可以获得最佳的观看体验。简而言之,DASH 协议可以根据用户的网络环境和设备性能自动选择最适合的视频质量,以确保视频的流畅播放和高质量观看。
CDN
CDN(Content Distribution Networks) 即内容分发网络,是一种在网络边缘部署节点的技术,通过靠近用户的部署位置,提高用户访问网站内容的速度和质量。以下是 CDN 的相关知识点:
CDN 的工作原理:CDN 通过将原始服务器上的内容缓存到分布在全球各地的服务器节点上,使用户请求能够从离用户最近的服务器节点获取内容,从而提高用户访问速度和性能。
CDN 的好处:CDN 可以帮助网站提高用户访问速度、减少带宽成本、提高网站的可用性、减轻服务器负载等。
CDN 的部署方式:CDN 可以采用两种部署方式,即自建 CDN 和使用第三方 CDN。自建 CDN 需要投入大量的资金和技术力量,而使用第三方 CDN 的成本较低,但需要考虑接入成本和服务质量等问题。
CDN 的缓存方式:CDN 缓存方式可以分为边缘缓存和中心缓存两种。边缘缓存是将内容缓存到离用户最近的服务器节点上,中心缓存是将内容缓存到核心节点上,然后由核心节点向各个边缘节点分发。
CDN 的工作流程:CDN 的工作流程可以分为 DNS 解析、请求路由、内容缓存和内容传输四个阶段。DNS 解析负责将用户请求路由到最佳的 CDN 节点,请求路由将请求分发到最近的边缘节点上,内容缓存负责将内容存储到缓存中,内容传输将缓存内容传输给用户。
Socket programming with UDP and TCP
网络协议由三个要素组成,分别是语义、语法和时序。
- 语义是解释控制信息每个部分的含义,它规定了需要发出何种控制信息,以及完成的动作与做出什么样的响应;
- 语法是用户数据与控制信息的结构与格式,以及数据出现的顺序;
- 时序是对事件发生顺序的详细说明。
人们形象地将这三个要素描述为:语义表示要做什么,语法表示要怎么做,时序表示做的顺序。
Socket programming
Goal: learn how to build client/server applications that communicate using sockets.
Two socket types for two transport services:
- UDP: unreliable datagram(数据报文,数据包)
- TCP: reliable, byte stream-oriented(以流为导向)
Building TCP and UDP Client-Server Interactions | by Matthew MacFarquhar | Dev Genius
This photo is a great visual representation of what is going on between the server and the client. In a Connection-oriented system, the server and client send these SYN, SYN-ACK and ACK messages to ensure the packet is successfully received, if this pattern(模式) is broken (i.e. one of these is not sent) then the packet can be re-sent.
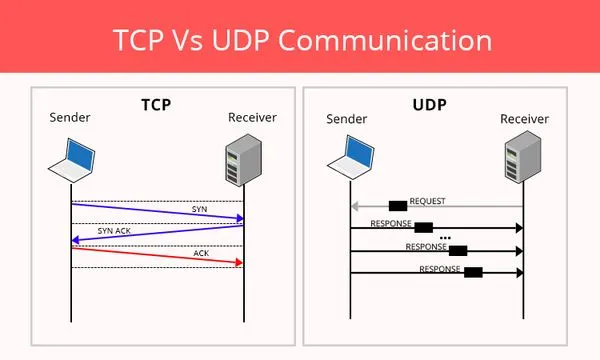
UDP 与 TCP 比较
Python 绝技 —— UDP 服务器与客户端 - i 春秋 - 博客园 (cnblogs.com)
为了更直观地比较 TCP 与 UDP 的异同,笔者将其整理成以下表格:
TCP UDP 连接模式 面向连接(单点通信) 无连接(多点通信) 传输可靠性 可靠 不可靠 通信模式 基于字节流 基于数据报 报头结构 复杂(至少 20 字节) 简单(8 字节) 传输速度 慢 快 资源需求 多 少 到达顺序 保证 不保证 流量控制 有 无 拥塞控制 有 无 应用场合 大量数据传输 少量数据传输 支持的应用层协议 Telnet、FTP、SMTP、HTTP DNS、DHCP、TFTP、SNMP
Client/server socket: UDP
Properties of UDP:
UDP - Client and Server example programs in Python | Pythontic.com
- The UDP does not provide guaranteed(放心的,可靠的) delivery of message packets. If for some issue in a network if a packet is lost it could be lost forever.
- Since there is no guarantee of assured(有把握的) delivery of messages, UDP is considered an unreliable protocol.
- The underlying mechanisms(底层机制) that implement(实现) UDP involve no connection-based communication. There is no streaming of data between a UDP server or and an UDP Client.
- An UDP client can send "n" number of distinct packets to an UDP server and it could also receive "n" number of distinct packets as replies from the UDP server.
- Since UDP is connectionless protocol the overhead(负载,开销) involved in UDP is less compared to a connection based protocol like TCP.
UDP 具体实现:
【Python】UDP/TCP_种花家 de 小红帽的博客-CSDN 博客
面向无连接型:无需对端是否存在,发送端可随时发送数据
特点:无连接,资源开销小,传输速度快,每个数据包最大是 64k,适用于广播应用
缺陷:传输数据不可靠,容易丢包;没有流量控制,需要接收方及时接收数据,否则会写满缓冲区
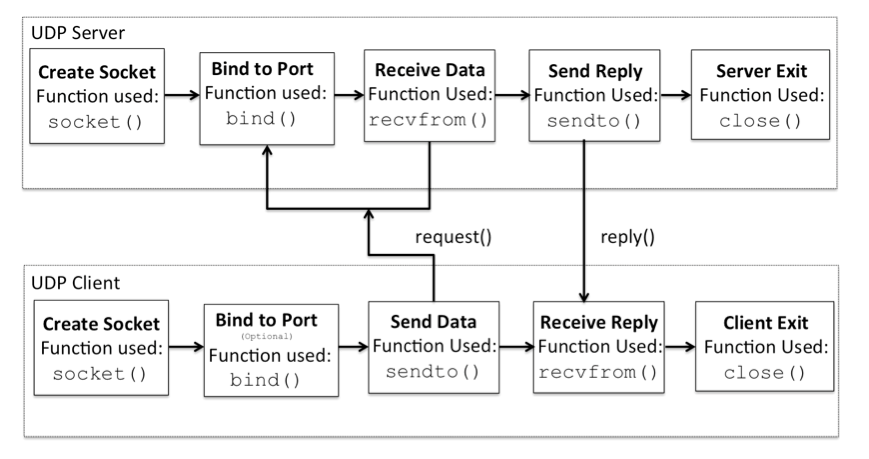
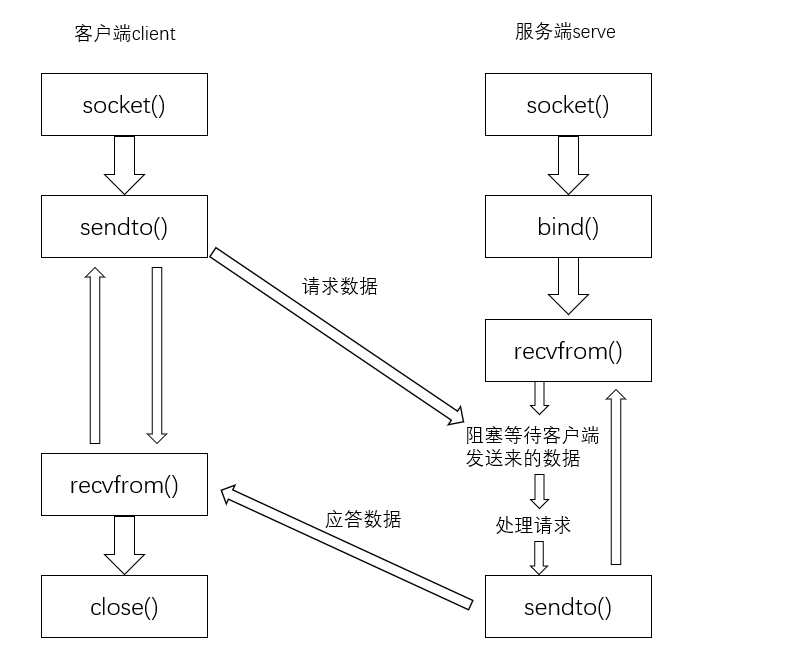
UDP 网络流程
- 保证 UPD 服务端的正常启动,进入到 recvfrom() 模式,阻塞等到客户端发送数据
- 开启 UDP 客户端,校准 IP 地址,通过 sendto() 模块进行数据发送
- 当服务端接收到接收到客户端发送来的数据,进行数据处理,并将应答数据发送给客户端
- 客户端接收到应答数据,可进行数据处理或重复发送数据,也可退出进程
UDP Serve 服务端
# coding=utf-8 from socket import * # 1. 创建套接字 udp_socket = socket(AF_INET, SOCK_DGRAM) # 2. 绑定本地的相关信息,如果一个网络程序不绑定,系统会随机分配 # ip地址和端口号,如果不指明ip,则表示本机的任何一个ip # 如果不指明端口号,则每次启动都是随机生成端口号 local_addr = ('', 12345) udp_socket.bind(local_addr) while True: # 3. 阻塞等待接收对方发送的信息 # 1024表示本次接收的最大字节数 recv_data = udp_socket.recvfrom(1024) # 4. 显示接收到的数据,并解码为gbk print(recv_data) print(recv_data[0].decode('utf-8')) # 5. 发送应答信息 # ip_addr = recv_data[1][0] # port = recv_data[1][1] addr = recv_data[1] data = '信息已收到' udp_socket.sendto(data.encode('utf-8'), addr) udp_socket.close()UDP Client 客户端
import socket # 1. 创建upd套接字 udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # 2. 准备服务端地址与端口号 # 127.0.0.1 代表自身ip地址,可向自身发送信息,也可指定ip地址发送信息 # 端口号随便填写一个未被占用的端口即可 # Linux环境有65535个端口号,前1024个端口号是系统端口号,系统端口号不能直接使用 addr = ('127.0.0.1', 12345) while True: # 3. 从键盘获取数据 data = input('请输入信息:') # 4. 通过sendto()发送信息到指定进程中 udp_socket.sendto(data.encode('utf-8'), addr) # 5. 通过recvfrom()阻塞等待获取应答数据 recv_data = udp_socket.recvfrom(1024) # 6. 处理应答数据,进行打印 print(recv_data) print(recv_data[0].decode('utf-8')) udp_socket.close()运行结果:(先运行服务端,再运行客户端)

Client/server socket: TCP
【Python】UDP/TCP_种花家 de 小红帽的博客-CSDN 博客
面向有连接型:双方先建立连接才能进行数据传输
特点:
双方都必须为该连接分配系统内核资源
完成数据交换后,双方必须断开连接,以释放系统资源
这种连接是一对一的,不适用于广播应用
TCP 提供可靠的数据传输,无差别、不丢失、不重复,且按序到达
相比于 UPD,TCP 数据传输速度慢、对系统资源要求较高
TCP 适合发送大量数据,UDP 适合发送少量数据
TCP 有流量控制,UPD 无流量控制
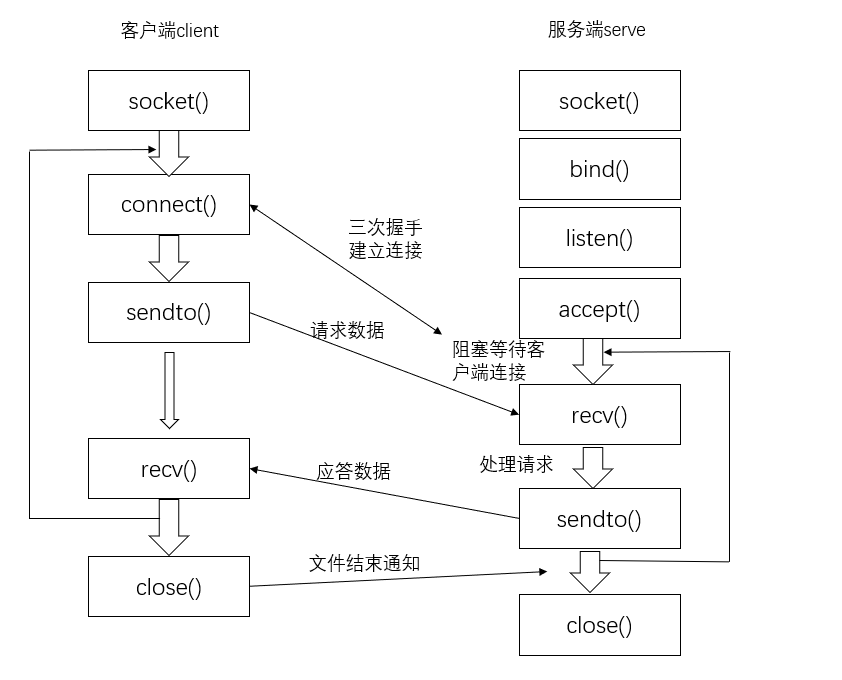
TCP 网络流程
TCP Serve 服务端
from socket import * # 1. 创建tcp套接字 tcp_serve_socket = socket(AF_INET, SOCK_STREAM) # 2. 设置socket选项,程序退出后,端口会自动释放 tcp_serve_socket.setsockopt(SOL_SOCKET, SO_REUSEADDR, True) # 3. 本地信息,第二个为端口 addr = ('', 12345) # 4. 绑定地址 tcp_serve_socket.bind(addr) # 5. 设置监听 # 使用socket创建的套接字默认的属性是主动的,使用listen将其变为被动的 # 参数代表等待连接时间最多60秒 tcp_serve_socket.listen(60) # 6. 如果有新的客户端来连接服务,就产生一个新的套接字,专门为这个客户端服务 # client_socket用来为这个客户端服务 # 原来的tcp_serve_socket就可以专门用来等待其他新用户的连接 client_socket, client_addr = tcp_serve_socket.accept() # 7. 阻塞等待客户端发送的信息 recv_data = client_socket.recv(1024) print("接收到信息:", recv_data.decode('gbk')) # 8. 发送应答信息 string = '已收到信息' client_socket.send(string.encode('gbk')) client_socket.close()TCP Client 客户端
import socket # 1. 创建TCP的套接字 tcp_client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 2. 目标ip信息 ip = input('请输入服务端ip:') port = int(input('请输入服务端port:')) # 3. 连接服务器 tcp_client_socket.connect((ip, port)) # 4. 提示用户输入数据 data = input('请输入要发送的信息:') # 5. 编码 tcp_client_socket.send(data.encode('gbk')) # 6. 接收服务端的应答数据 recv_data = tcp_client_socket.recv(1024) print('收到应答数据:', recv_data.decode('gbk')) # 7. 关闭套接字 tcp_client_socket.close()运行结果:
如果忘记设置端口的关闭,非正常退出会导致端口一直被占用
linux 环境在终端执行
ps aux | grep py查看运行的进程,然后kill -9 pid杀掉进程建立连接(三次握手)
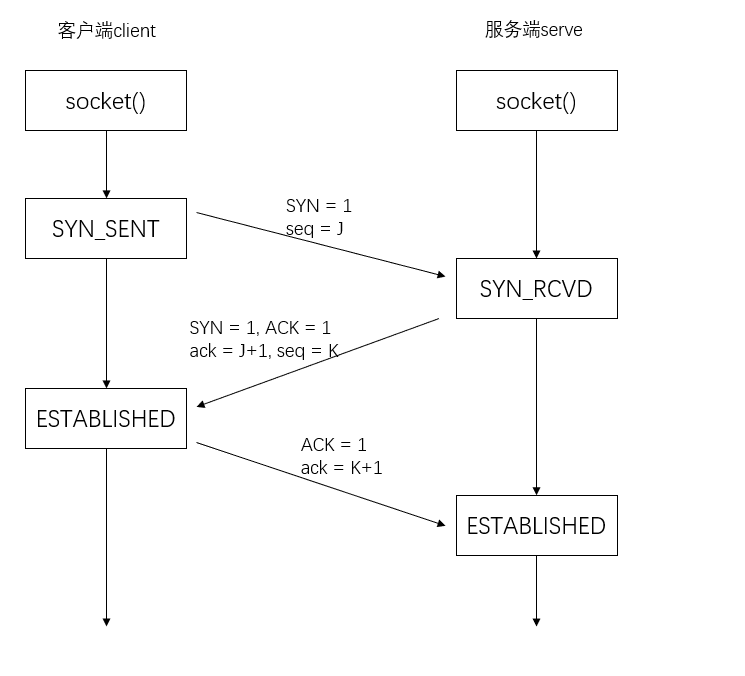
SYN:连接请求 ACK:确认 FIN:关闭连接 seq:报文信号 ack:确认信号
第一次握手:client 标志位 SYN 置 1,随机产生一个 seq=J,并将该数据包发送给 serve,client 进入 SYN_SENT 状态,等待 serve 确认
第二次握手:serve 收到数据包后由标志位 SYN=1 知道 client 请求建立连接,serve 将 SYN 和 ACK 都置 1,ack(number)=J+1,+1 是逻辑加一(加密),随机产生一个值 seq=K,并将该数据包发送给 client 以确认连接请求,serve 进入 SYN_RECV 状态
第三次握手:client 收到确认,检查 ack 是否为 J+1(解密),如果正确则将标志位 ACK 置 1,ack=K+1,并将该数据包发送给 serve,serve 检查 ack 是否为 K+1,如果正确则建立连接成功,client 和 serve 同时进入 ESTABLISHED 状态,完成三次握手,随后 client 和 serve 之间可以传输数据
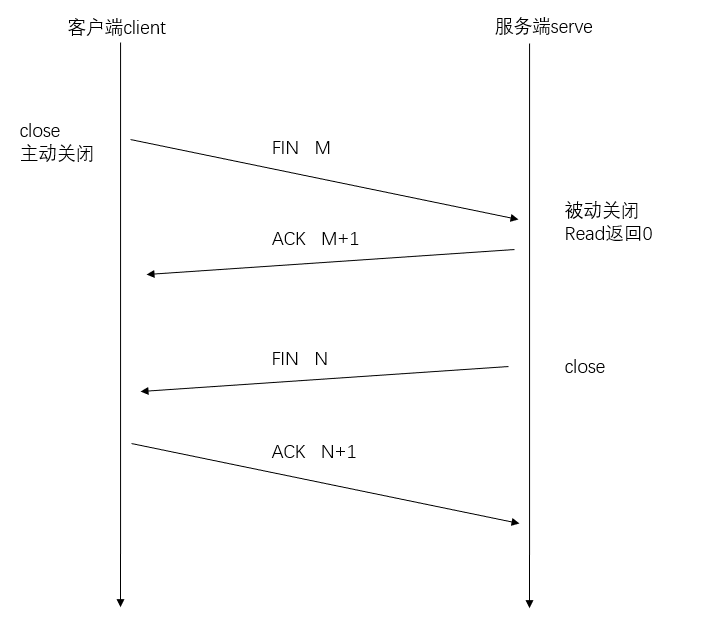
断开连接(四次挥手)
第一次挥手:client 发送一个 FIN,用来关闭 client 到 serve 的数据传送
第二次挥手:serve 收到 FIN 后,发送一个 ACK 给 client,确认序号为收到序号 + 1,表示还有剩余数据未传送完
第三次挥手:serve 发送一个 FIN,用来关闭 serve 到 client 的数据传送
第四次挥手:client 收到 FIN 后,接着发送一个 ACK 给 serve,确认序号为收到信号 + 1

Q: TCP 传输中的 Segment 是什么?
A: 是该协议负责传输的数据单元的专用名词。在 TCP 协议中,分段(segment)是指将传输的数据分割成多个较小的部分,以便更有效地在网络上传输。每个分段包含在 TCP 首部中的控制信息,如端口号、序列号和确认号等,以及在数据字段中携带的有效负载部分。分段的大小可以根据不同的网络条件进行调整,以最大程度地减少重传或延迟。在接收方,TCP 会将收到的分段重新组合成完整的数据,以保证传输的准确性和完整性。